
收集整理了下 2022年卖家选品踩坑的案例,亏损情况小的几万,大的几十万,更重要的是大半年时间耗进去了。
背后的原因很多,最集中的两个难题:
1)对未来市场需求的误判,热潮过去就卖不动了
2)对自身产品竞争力的误判,上架后很快被卷“死”了
误判是难免的,做好以下几个维度的工作,能大大降低风险。
功利一点来说,尤其是做开发的同学,能否说服老板、运营做你的品,分配多少的资源用于后面的推广,需要你有更体系化的思维和阐述。
先上个脑图(清晰大图找鸥鹭客服领取)
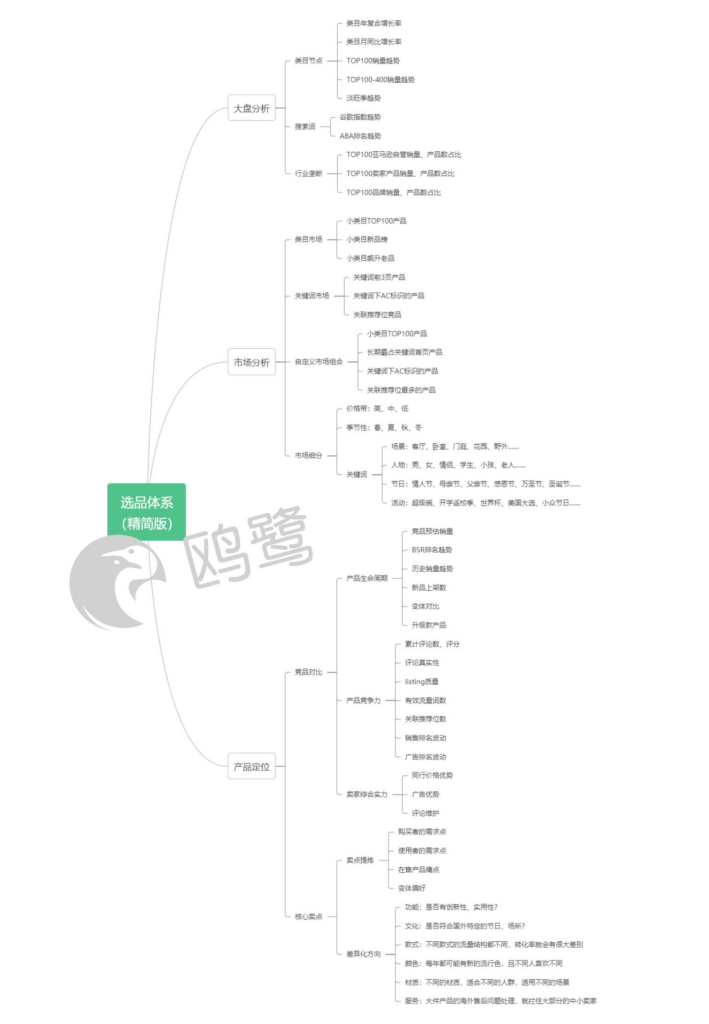
我们本周重构了鸥鹭后台的功能架构,用户会更容易理解鸥鹭的特色!
新版的“竞品透视”模块,帮助卖家全面透视一个asin的各维度数据,更深入评估一款产品的市场竞争力,从而降低选品风险。
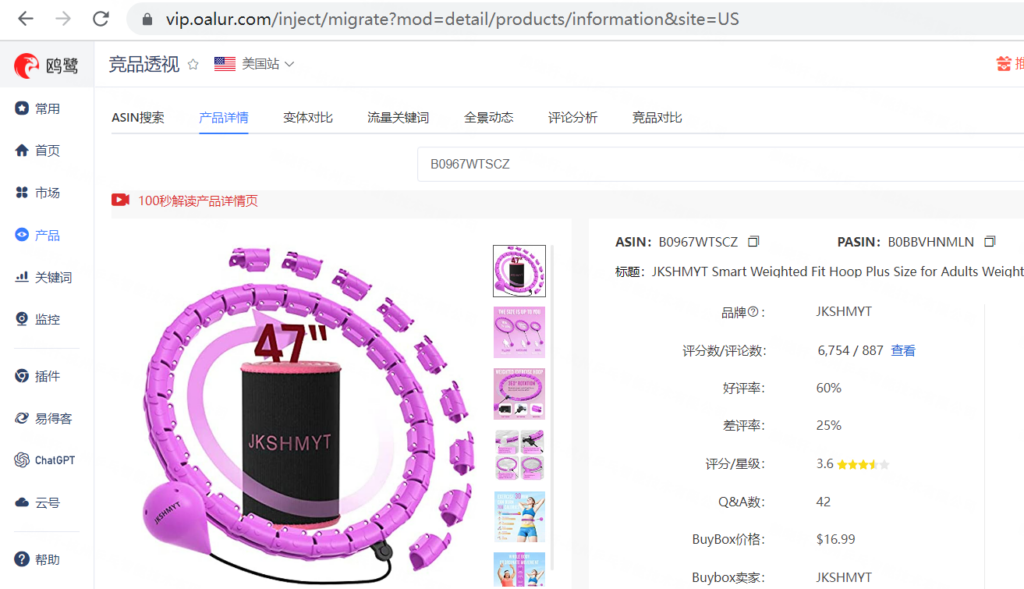
下面从三个层面,分享一下实际分析的侧重点。
1、大盘层面
大盘数据要看,但不必过度解读,重点看:类目淡旺季趋势、头部垄断情况。
类目淡旺季趋势,除了销售数据趋势之外,参考类目大词的ABA排名趋势、和谷歌指数趋势。
以女装类目为例,每年下半年需求会收缩,要控制备货;亚马逊自营垄断程度不高,TOP100产品以第三方卖家为主。
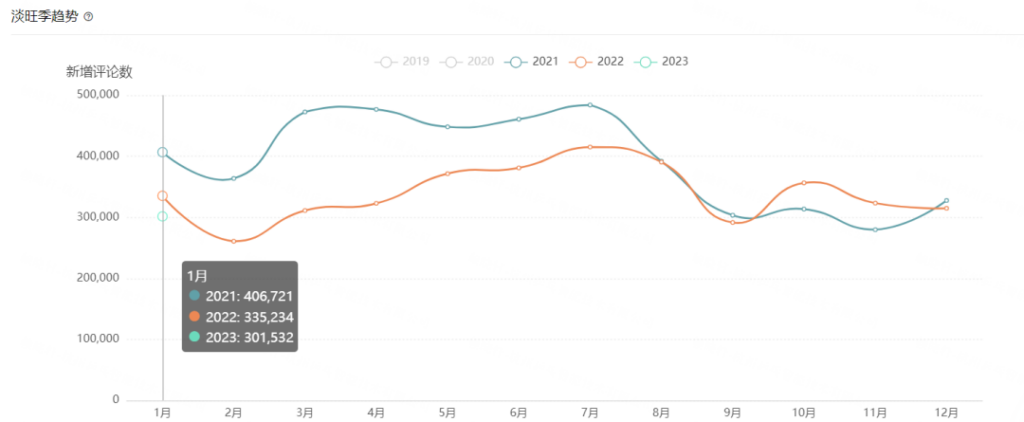
亚马逊官方基于自身立场,可能永远不会告诉你:“这个类目的亚马逊自营垄断很高,卖家慎入!”
这个层面的数据分析工作量其实一点都不重,但是直接决定你是否入场、何时入场,没把控好的话,后续的努力可能前功尽弃。
还有一点,假如你关注的类目里,中国卖家占比很少?那更要警惕,大概率是门槛的或者深坑的!
2、市场层面
就新品而言,“类目大盘”和“目标市场”是两个分析层面,不应混淆。
现在测算市场容量,需要更精细、更聚焦,自定义一批产品样本做聚焦的市场竞争力分析,只看类目维度的统计容易失焦。
假如做季节性产品,更要聚焦关键词维度的市场分析,市场分析做得越好,产品定位就不容易跑偏。
1)看存量
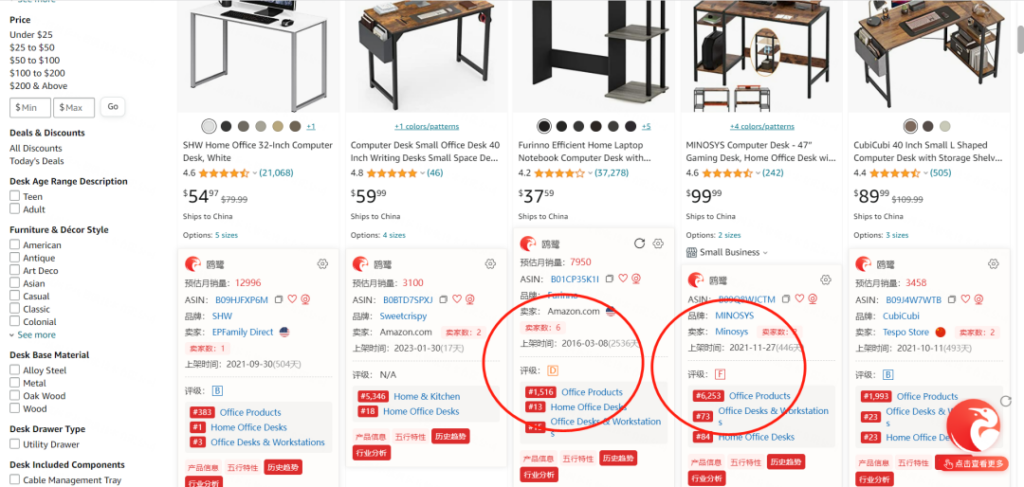
分析在售头部产品,其实是在分析“存量”的市场。
我们建一个 ASIN 样本库做调研,范围可包括:
-小类目TOP100的产品
-长期霸占关键词首页的产品(自然位、广告位分开看)
-关键词下AC标识的产品
-关联推荐位最多的产品
这批产品一般覆盖了存量市场份额的60%以上,再分析这批产品的数据分布:销量、BSR排名波动、价格、评论数、评分、listing质量、品牌垄断度、卖家垄断度、新品占比等,得到的结论会比类目视角的统计更有效一些。

我们分析头部垄断时,通常要参考竞品老链接的累计评论数,但因为刷单的存在,很多老链接的评论数是有水分的,竞争力其实没有想象中的大!
借助fakespot的功能,可以查很多老链接的评论真伪度:
A:90%-100%的真实评论,星级在4星以上
B:80-89%的真实评论,星级在3星以上
C:65%-79%的真实评论,星级在2星以上
D:45-64%的真实评论,星级在1.5星以上
F:45%以下的真实评论,星级在1星以上
2)看增量
两个角度评估未来增量,有些卖家不够重视这块。
第一,关注类目新品榜、或者用软件监控竞对的新品,分析未来几个月是否会持续热销成为爆品。
除了研究新品本身,还要看背后卖家的实力,有没中国卖家扎堆的情况。
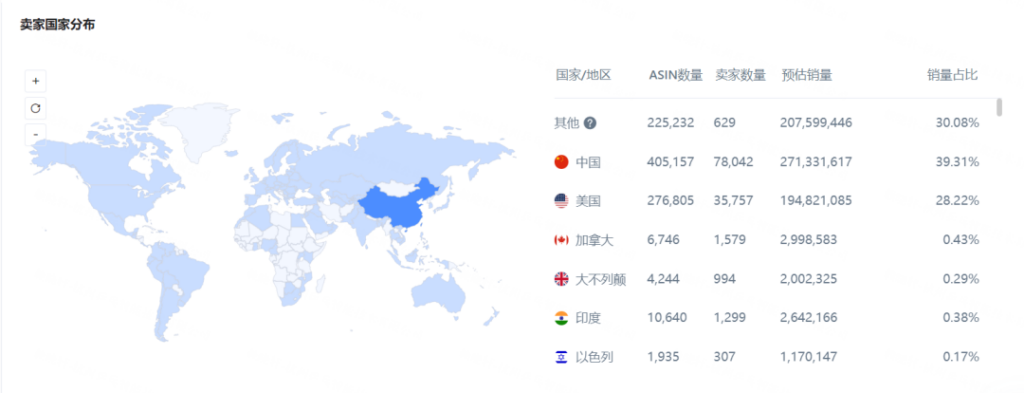
特别有实力的精品卖家,观察他们店铺的其它产品,就会发现他们在价格上、广告推广、评论维护上都做得很稳。第二,调研国内自有供应链近期有什么新品,有可能打破存量市场格局的。
3、产品层面
能否做出差异化,这个层面的思考是分水岭。
都知道要研究评论,分析客户画像和需求。大道理说起来容易,用ChatGPT可以写出100个版本,但做起来难。
这里有个误区,“客户画像分析”不是分析一个具体的自然人群,“这个产品对标的是Z世代的人群”这种说法相当于伪命题。
最终落到我们产品开发上,客户画像都是在分析一个个需求点的维度组合,不论是做电商还是其它零售端的行业,都是如此。
目前做差异化的方向:
1)功能,是否有创新性、实用性?
2)文化,是否符合国外特定的节日、场所?
3)款式,不同款式的流量结构都不同,转化率就会有很大差别
4)颜色,每年都可能有新的流行色,且不同人喜欢不同
5)材质,不同的材质,适合不同的人群,适用不同的场景
6)服务,大件产品的海外售后问题处理,就拦住大部分的中小卖家
这块信息的数据化是个技术难点。
大部分电商平台的属性标签数据,都是比较乱的,“红色”和“砖红色”可能要不要归类,如何归类,把数据清洗后并能提供业务上的参考。
亚马逊官方在后台提供了一些产品功能特征维度的统计数据,但那还远远不够,鸥鹭也在研究更好的解决方案。
目前,卖家还是得花一些时间整理产品调研表格。
ChatGPT证明了一个最简单的道理:提问的能力,才是真正稀缺且重要的。
信息差会越来越小,数据分析的门槛也会越来越低。
大家对于选品有什么思考和问题,欢迎来留言区和鸥鹭社群交流~!
发表回复